ELFの構造と種類
低レベルプログラミングの5.3.1から5.4の内容をまとめた.
ELFファイルの種類
ELF(Excutable and Linkable Format:実行とリンクが可能なフォーマット)は,*nixシステムのオブジェクトファイルとして典型的なフォーマットである.ELFは以下の三種類のファイルをサポートする.
再配置可能なオブジェクトファイル(relocatable object file)
コンパイラが作成するオブジェクトファイル。 再配置(relocation)は,プログラムの各部に決定的なアドレスを割り当て,全てのリンクが適切に解決されるようにプログラムのコードを変更する処理のことである.つまり,絶対アドレスによってあらゆる種類のメモリアクセスを解決する.再配置は,プログラムを構成する複数のモジュールが互いを参照している時に必要になる.モジュール別のファイルでは,メモリに置かれる順序が固定されていないから,絶対アドレスはまだ決まらない.リンカがこれらのファイルを結合して実行可能なオブジェクトファイルを生成する.実行可能なオブジェクトファイル(excuteble object file)
そのままメモリにロードして実行できるファイル. これは基本的に,コードとデータとユーティリティ情報を構造化したストレージである.共有オブジェクトファイル(shared object file)
必要な時にメインプログラムがロードできるファイル. 動的にリンクされるので,動的ライブラリとも呼ばれWindows OSでは .dll ファイルとして知られている.*nixシステムでは,ファイル名が .so (shared object)で終わることが多い.
リンカの役割
あらゆるリンカの目的は,再配置可能なオブジェクトファイルの集合を受け取って,一個の実行可能な(あるいは共有)オブジェクトファイルを作成すること.そのためにリンカは次の仕事を行う.
- 再配置(relocation)
- シンボルの解決(symbol resolution)
シンボル(関数や変数の名前)が参照されるたびに,リンカはオブジェクトファイルを変更して,命令オペランドのアドレスに対応する部分を正しい値で埋める必要がある.
ELFの構造
リンカから見たビュー(linking view)
セクションによって構成される.
これを記述した「セクションヘッダ」の表はreadelf -Sで観察することができる.個々のセクションは次のうちのいづれかである.
- メモリにロードされる生のデータ(raw data)
- 他のセクションに関する整形されたメタデータ
ローダが使う情報(ex: .bss),リンカが使う情報(ex: 再配置表),デバッガが使う情報(ex: .line)がある.
コードとデータはセクションの中に格納される.
ローダから見たビュー(excution view)
セグメントによって構成される.
これを記述する「プログラムヘッダ」の表をreadelf -lで観察することがきる.この表のエントリには次の記述が入る.
- システムがプログラムを実行するために必要となる情報
- 0個以上の「プログラムヘッダ」セクションを含むELFセグメント
プログラムヘッダは仮想メモリと同じパーミッション集合を持つ.それぞれ開始アドレスをもつ複数のセグメントが,連続的なページで構成される別々のメモリ領域にロードされる
ELFファイルのセクション
具体的なセクションの一部を挙げる.
- .text: マシン語命令が入る
- .rodata: read onlyデータが入る
- .data: 初期化されたグローバル変数が入る
- .bss: 読み書き可能なグローバル変数が0で初期化される(=未定義)
全てがゼロ埋めされているため,その内容をオブジェクトファイルにダンプする必要はない.その代わりセクションの合計サイズが格納される(そのメモリをゼロにする高速な方法はOSが知っているだろう).アセンブリ言語ではresb,reswなどのディレクティブをsection .bssの後に置くことでこのセクションにデータを入れることができる. - .rel.text: .textのために再配置表が入る
このテーブルはリンカのためにあり,このオブジェクトファイル専用のローディングアドレスを選択した後で.textを書き換えなければいけない場所を記録する目的で使われる. - .rel.data: モジュール内で参照されているデータのための再配置表が入る
- .debug: プログラムをデバッグするためのシンボルテーブルが入る
もしCやC++で書かれたプログラムなら,グローバル変数についての情報だけでなく(これらは.symtabに入る)ローカル変数についての情報もここに入る. - .line: コードの断片とソースコード内の行番号の対応を定義する
高級言語のソースコードにおける行と,アセンブリ命令との対応が単純ではないのでこれが必要なる. - .strtab: 文字列が配列のように格納される
他のセクションは文字列を直接使うのではなく, .strabのインデックスを使う - .symtab: シンボルテーブルが入る
プログラマがラベルを定義したら必ずNASMがシンボルを作る.この表にはユーティリティ情報も含まれる.
ライブラリ
ライブラリには動的と静的の二種類がある.
静的ライブラリ
再配置可能なオブジェクトファイルから構成される.これらはメインプログラムにリンクされて実行ファイルに組み込まれる.静的ライブラリの実態はエントリポイントがなく中途半端な実行ファイルである. Windowsの世界ではファイルには.libという拡張子がつく.Unixの世界では.oファイルかさもなくば複数の.oファイルを内部にもつアーカイブの.aが用いられる.
動的ライブラリ
共有オブジェクトファイルとも呼ばれる.これがプログラムにリンクされるのはそのプログラムの実行中である. Windowsの世界で評判が悪い.dllファイルがこれである.Unixの世界では .so という拡張子がつく. 必要になったタイミングでロードされる.ライブラリ自身が完全なオブジェクトファイルなので,外部でライブラリの機能が使えるようにどんなコードを提供するかを調べるために必要なメタ情報を持っている.この情報をローダが使ってエクスポートされている関数とデータの正確なアドレスを決定する. プログラムは共有ライブラリをいくつでも使うことができるが,アドレスが衝突しないようにするために以下の二つの方策が取られる.
実行時(ライブラリをロードしている時)に再配置を行う
可能だが,そうした場合に複数のプロセスで同じライブラリを重複して読み込むことになってしまう. また, .dataは書き換え可能であるため再配置を行う必要がある.これを回避するためにはグローバル変数を撤廃する必要がある. また,再配置の際に.textを書き換える必要があるためこのセクションに書き込みを許可する必要がありセキュリティ上のリスクが生じる.さらに, ある実行ファイルが複数のライブラリを必要とする時には全ての共有オブジェクトについて.textを書き換えることになり時間がかかってしまう.PIC(Position Independent Code:位置に依存しないコード)を書く
rip相対アドレッシングを活用することで絶対アドレスを排除することで,メモリ上のどこに配置されても実行可能なコードを書くことができる.これにより.textセクションを複数のプロセスで共有することができる.
動的ライブラリを使うことで,複数のプロセスでコードの一部を共有することができディスクとメモリの節約になる.
動的ライブラリに特有のセクション
- .dynsym: ライブラリの外にみせるシンボルが入る
- .hash: ハッシュ表. .dynsymでシンボルをサーチする時間を短縮できる
- .Fdynstr: 文字列群が入る.これらをdynsymからインデックスで参照する.
【Exercism】Clojure Trackについてのノート Part.1
この記事ではExercismのClojure Tracksの初めの10題について自分の思考や他の人の解答を見て考えたことをまとめておこうと思います。
Hello World
何はともあれ初めはやはりHello Worldから。
(ns hello-world) (defn hello [] (str "Hello, World!"))
Two Fer
次の問題は、引数として名前の文字列Xが与えられた場合にはOne for X, one for me.、何も与えられていない場合にはOne for you, one for me.を返すというものです。これをはじめは次のように書いていました。
(ns two-fer) (defn two-fer ([] (str "One for you, one for me.")) ([name] (str "One for " name ", one for me.")))
ただ、引数文字列が与えられない場合は与えられる場合の特殊な形と考えられるので、もっと簡単に次のようにすることができます。
(defn two-fer ([] (two-fer "you")) ([name] (str "One for " name ", one for me.")))
Reverse String
reverse関数を使わずに文字列を逆にするという問題です。これは、リストに対するinto関数がconj関数を使っていることを利用して解きました。つまり、リストに対してconjを行った場合には新しい要素が先頭に追加されるため、文字列を全体として逆向きにすることができるということです。
解答は次のようになりました。
(ns reverse-string) (defn reverse-string [s] (apply str (into () s)))
Bob
この問題はやる気のないBobの返答を再現する関数を作成する問題です。英語の文章を読むのが苦手すぎて問題文だけでは問題の趣旨が理解できなかったので、テストをみたり他の人の解答を真似したりしてなんとか完成しました。
この問題の個人的なポイントは以下の二点です。
(ns bob (:require [clojure.string :as string])) (defn- only-uppercase? [text] (let [s (filter #(Character/isLetter %) text)] (and (seq s) (every? #(Character/isUpperCase %) s)))) (defn response-for [s] (let [question (string/ends-with? (string/trimr s) "?") uppercase (only-uppercase? s)] (cond (string/blank? s) "Fine. Be that way!" (and question uppercase) "Calm down, I know what I'm doing!" question "Sure." uppercase "Whoa, chill out!" :else "Whatever.")))
Armstrong Numbers
与えられた数がArmstrong Number、日本語ではナルシシスト数かどうかを判定する問題です。 処理の流れとしては、
- 与えられた数値を文字列化し、その長さを数えて桁数を取得
c->iで文字列を各桁の数字からなるシーケンスに変換powで(各桁の値)桁数を計算- 求めた値を合計して、元の値と比較
となります。
この問題で詰まった点は、Math/powを使うと大きな数に対しては値が不正確になり計算が合わなくなるという点です。これを解決するために(apply *' (repeat e %))で冪乗を計算しています。
また、StringではなくCharacterをうまく数値に変換してくれる関数が標準にはなかったので、(- (int c) 48)としてASCIIコードから数値の値を求めています。
(ns armstrong-numbers) (defn armstrong? [num] (let [s (str num) e (count s)] (letfn [(c->i [c] (- (int c) 48)) (pow [n] (apply *' (repeat e n)))] (= num (reduce +' (map (comp pow c->i) s))))))
この問題を解く際、はじめは与えられた数値を文字列に変換せず、数学的な操作によって桁数や各桁の数を求めていました。コードは以下の通りです。
(ns armstrong-numbers) (defn- digits-vec [num] (loop [n num v []] (if (zero? n) v (recur (quot n 10) (conj v (rem n 10)))))) (defn- pow [base n] (apply * (repeat n base))) (defn armstrong? [num] (let [digits (digits-vec num) c (count digits)] (= num (reduce + (map #(pow % c) digits)))))
ただ数値のままだと思いのほかコードが長くなってしまったので、文字列として処理してすることにしました。文字列として処理することの利点は、文字列がシークエンスの一種であるためmapやreduceといった関数で扱いやすい点です。ただ、文字列として扱った場合だと処理速度が遅くなるような気がしたので実行時間を計測してみることにします。
こちらのコードで数値と文字列を処理する関数にどちらも1万回、最大のナルシシスト数の判定をさせ、それを10回繰り返してみましたが、両者にあまり速度の違いはないようです。
1th str:"Elapsed time: 1297.593372 msecs" num:"Elapsed time: 1166.087944 msecs" 2th str:"Elapsed time: 1067.562394 msecs" num:"Elapsed time: 1076.284028 msecs" 3th str:"Elapsed time: 1111.623312 msecs" num:"Elapsed time: 1048.309024 msecs" 4th str:"Elapsed time: 1101.764114 msecs" num:"Elapsed time: 1078.378682 msecs" 5th str:"Elapsed time: 1083.469371 msecs" num:"Elapsed time: 1065.887519 msecs" 6th str:"Elapsed time: 1071.725037 msecs" num:"Elapsed time: 1120.12435 msecs" 7th str:"Elapsed time: 1073.346986 msecs" num:"Elapsed time: 1087.391752 msecs" 8th str:"Elapsed time: 1096.079852 msecs" num:"Elapsed time: 1125.990081 msecs" 9th str:"Elapsed time: 1096.441165 msecs" num:"Elapsed time: 1094.644011 msecs" 10th str:"Elapsed time: 1094.838953 msecs" num:"Elapsed time: 1140.874014 msecs"
実行速度の測定方法がこれで正しいか確証が持てないので、間違いなどございましたら教えていただけると幸いです。
RNA Transcription
与えられたDNA塩基配列から生成されるRNAを出力する関数を書けという問題。これは全くいい回答が書けなかったです。私の回答は以下の通りです。
(ns rna-transcription) (defn trans-ncleotide [nc] (case nc \A \U \C \G \G \C \T \A (throw (AssertionError. "Invalid nucleotide")))) (defn to-rna [dna] (apply str (map trans-ncleotide dna)))
テストを見るとAssertionErrorの発生を前提としていたので無理矢理AssertionErrorを投げてみたのですが、これはclojure.coreのassert関数を利用した方が良かったようです。私的にとても参考になったのはesideboさんの解答です。
(ns rna-transcription) (defn to-rna [dna] (let [rna (->> dna (map {\G \C \C \G \T \A \A \U}) (apply str))] (assert (= (count dna) (count rna))) rna))
連想配列をDNA翻訳のための関数として利用している部分が秀逸だと思います。
Run Length Encoding
Run-length encodingという連続するアルファベットや空白文字を数字で表すことで文字列を短縮できるエンコードを実装する問題。この問題は良い解答が書けたと思ったのですが、それほどよくなかったです。私の解答は以下の通りです。
(ns run-length-encoding) (defn run-length-encode "encodes a string with run-length-encoding" [plain-text] (let [segs (map first (re-seq #"([a-zA-Z ])\1*" plain-text))] (apply str (map #(str (when (< 1 (count %)) (count %)) (first %)) segs)))) (defn run-length-decode "decodes a run-length-encoded string" [cipher-text] (apply str (for [[_ n c] (re-seq #"(\d*)([a-zA-Z ])" cipher-text)] (let [i (if (empty? n) 1 (Integer/parseInt n))] (apply str (repeat i c))))))
正規表現を使っているのはよいですが、その後の処理が読みにくくなってしまっています。この問題の解答で私が良いと思ったのはamscottiさんの解答です。
(ns run-length-encoding (:require [clojure.string :as str])) (defn run-length-encode "encodes a string with run-length-encoding" [plain-text] (str/replace plain-text #"(\D)\1+" (fn [[a b]] (str (count a) b)))) (defn run-length-decode "decodes a run-length-encoded string" [cipher-text] (str/replace cipher-text #"(\d+)(\D)" (fn [[_ c l]] (apply str (repeat (read-string c) l)))))
clojure.string/replaceを使うことで簡明に書くことが出来ていて感動しました。
ISBN Verifier
本のISBN-10として正しい文字列かどうかを判定する問題。これはかなり良い解答が書けたと思っています。
(ns isbn-verifier) (defn isbn? [isbn] (if-let [coll (re-matches #"(\d)-?(\d{3})-?(\d{5})-?(\d|X)" isbn)] (zero? (mod (->> (reverse (apply str (rest coll))) (map-indexed #(case %2 \X 10 (* (inc %1) (- (int %2) (int \0))))) (reduce +)) 11)) false))
最初のif-letで形式が正しくないものを全てきちんと弾けている点が特に気に入っています。
Word Count
文章中に存在するアルファベットの出現回数を連想配列に変えて返す関数を作成する問題です。frequenciesというそのまんまの関数があったので、正規表現で単語ごとに区切ったものをそのまま渡して完成です。
(ns word-count (:require [clojure.string :as str])) (defn word-count [s] (frequencies (re-seq #"\w+" (str/lower-case s))))
これと全く同じ問題がTour of Goにありましたね。問題文でも言及されていましたね。
Anagram
与えられたリストの中から与えられた単語のアナグラムになっているものを探す関数を作成する問題です。頭文字のみを小文字にして単語をソートし、それをリストの単語と比較しています。
(ns anagram (:require [clojure.string :as str])) (defn anagrams-for [word prospect-list] (letfn [(sort-word [s] (sort (apply str (str/lower-case (first s)) (rest s))))] (let [w (sort-word word)] (filter #(and (not= word %) (= w (sort-word %))) prospect-list))))
今後もExercismを続けて76題全部終わらせたいと思います。
Windows 10 に Virtual Box を使って Zorin OS 15.1 を導入
必要なもの
- Virtual Box
- 最低 8GB のストレージ空き容量
Zorin OS の ISO ファイルを入手
公式サイトから CORE をダウンロード
新しい仮想マシンを作る
「新規」をクリック
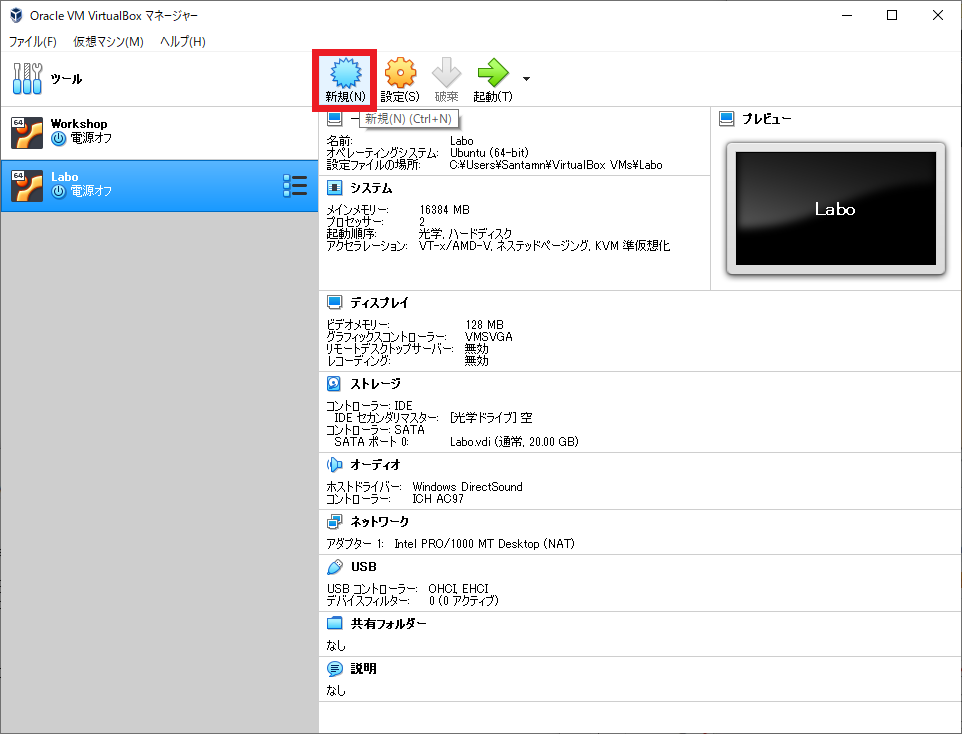
名前、タイプ、バージョンを指定する
タイプは Linux、バージョンは Ubuntu(64-bit)です。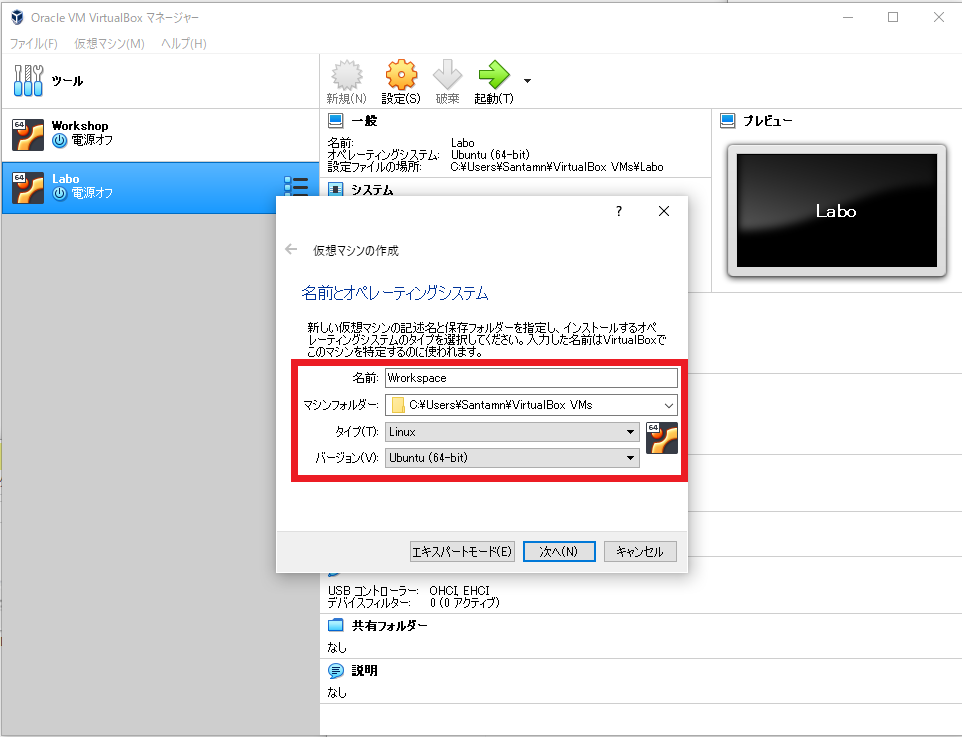 名前誤字ってますね。あとから見て気が付きました。恥ずかしいです。
名前誤字ってますね。あとから見て気が付きました。恥ずかしいです。メモリサイズの指定
メモリは 2GB 以上が推奨されています。ここでは 16GB とします。
ハードディスクのファイルタイプを指定
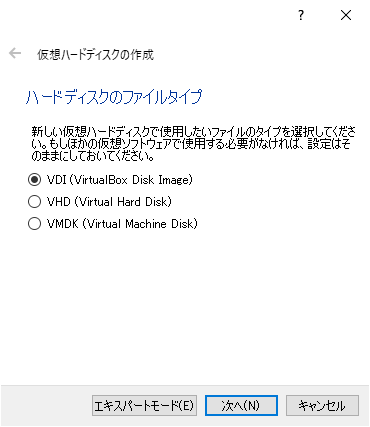
ハードディスクの作成
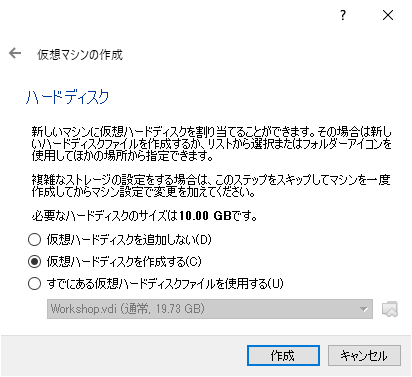
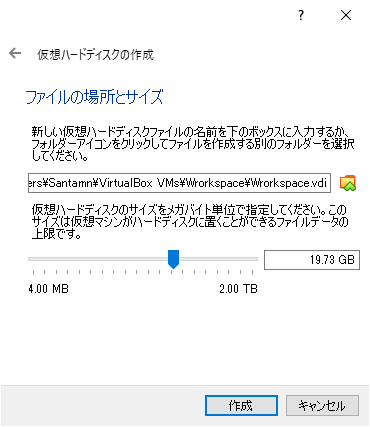
ハードディスクのサイズを指定
余裕をみて、ここでは約 20GB 分の容量を取っておきます。
作成した仮想マシンをカスタマイズする
設定画面を開く
作成した仮想マシンを選択した状態で「設定」を選択します。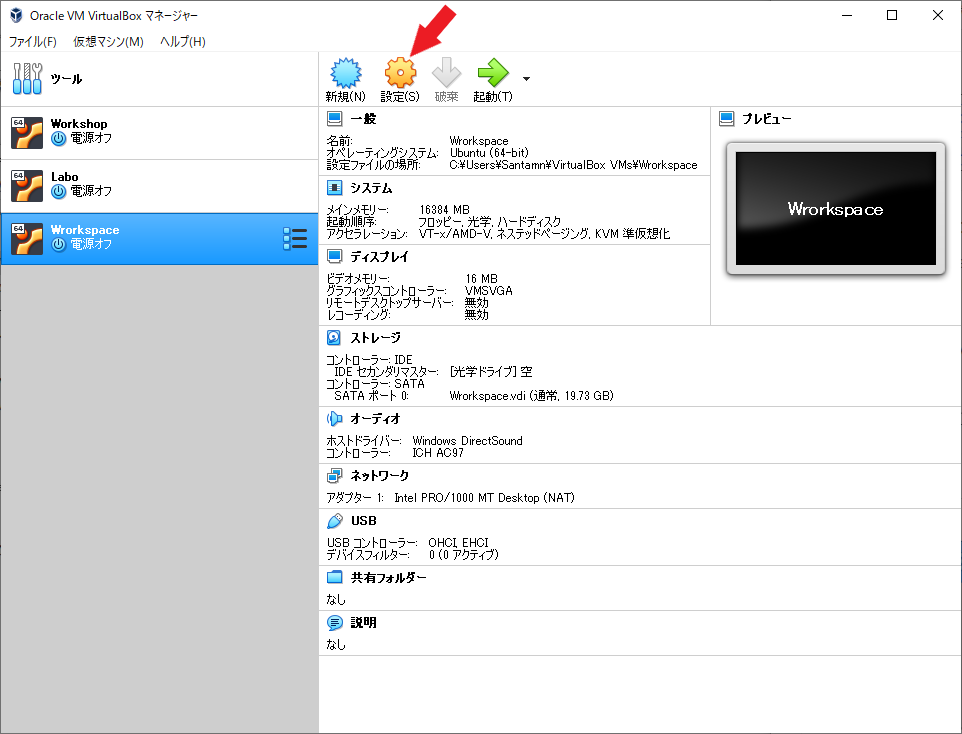
CPU サイズの指定
もともとの設定ではプロセッサーの数が1になっているので、2に増やします。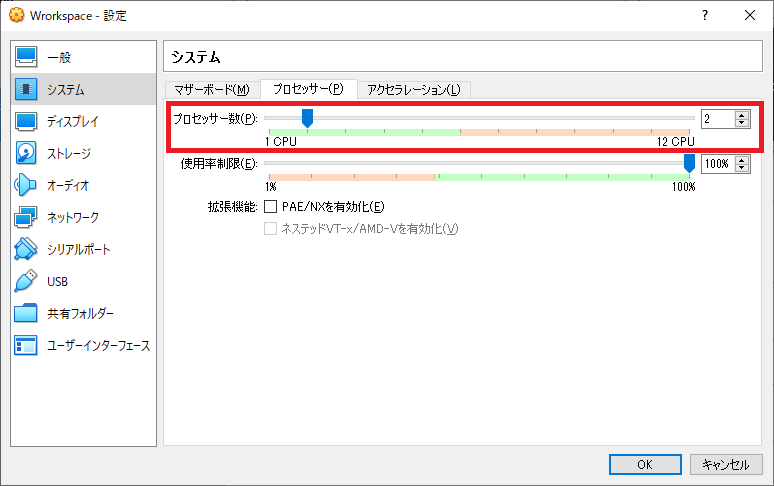
起動順序の指定
フロッピーディスクからチェックをはずし、図のような起動順序にします。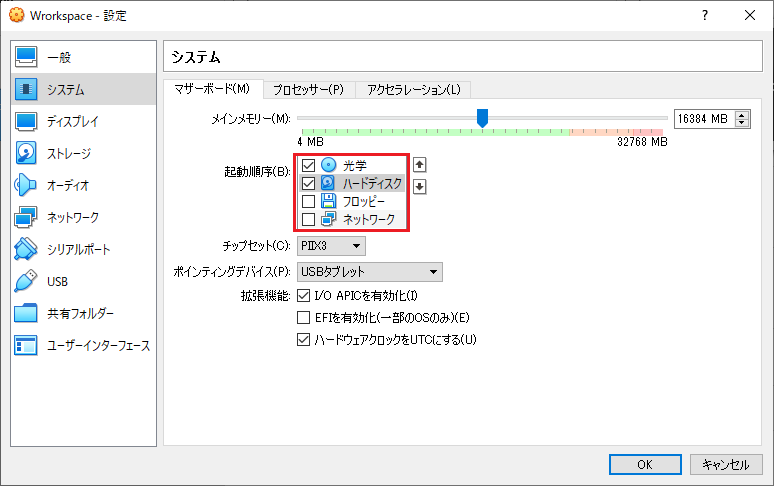
ビデオメモリの設定
ビデオメモリを 128MB にします。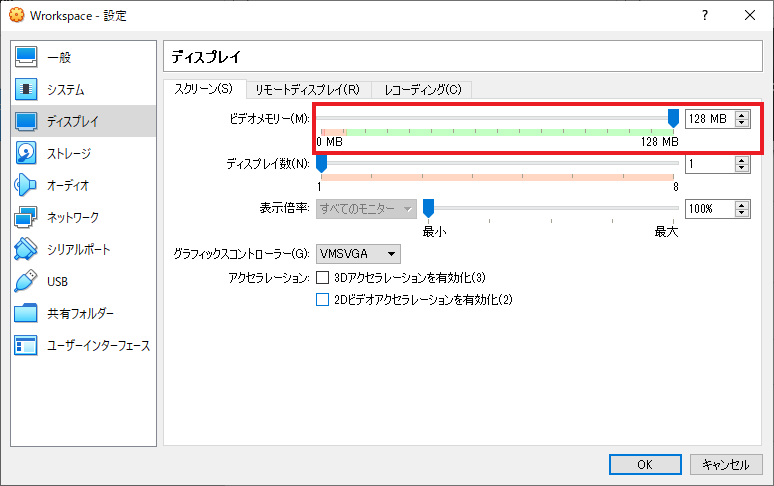
クリップボードの共有
クリップボードの共有とドラッグ&ドロップをどちらも双方向にします。このあと、Guest Addition CD イメージの挿入を行えば、コピペや全画面への拡大が可能になります。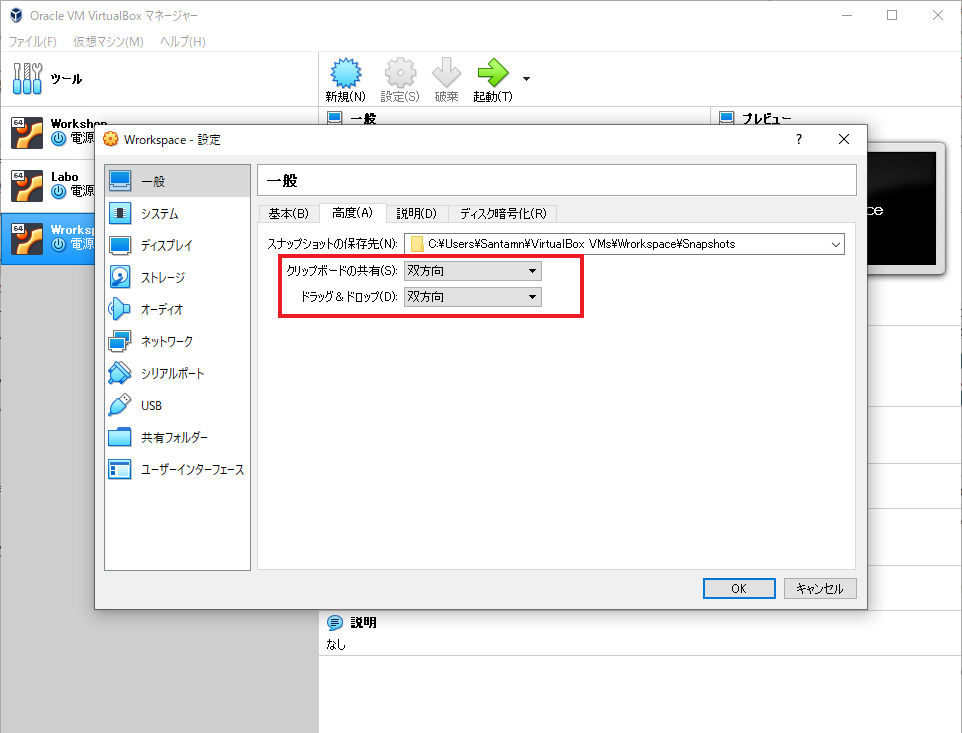
仮想光学ディスクファイルの指定
先ほどダウンロードしておいた Zorin OS のディスクイメージを指定します。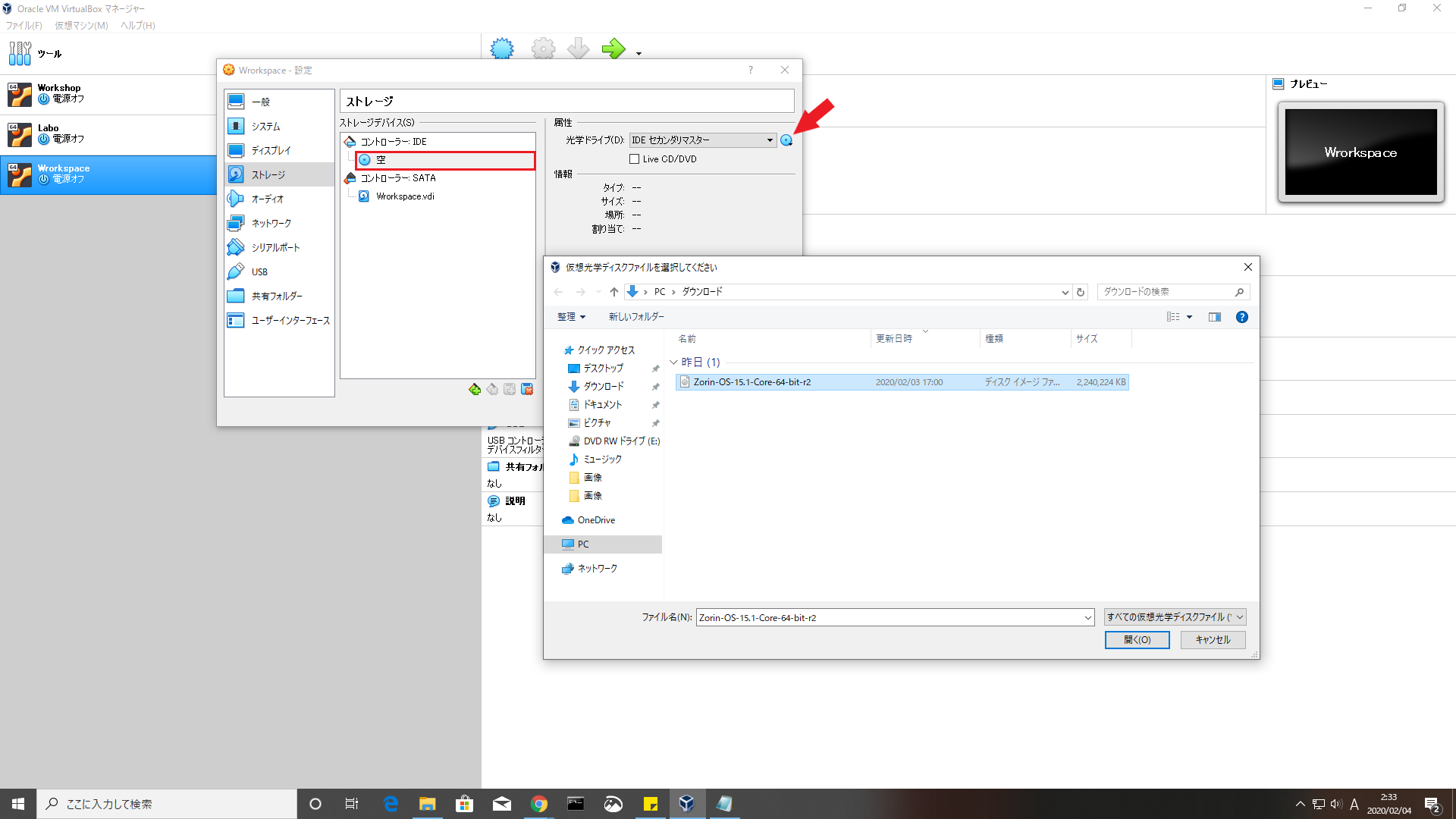
起動後の設定
以上の設定を行ったあと、「起動」を押します。その後、以下のような流れで設定を行っていきます。
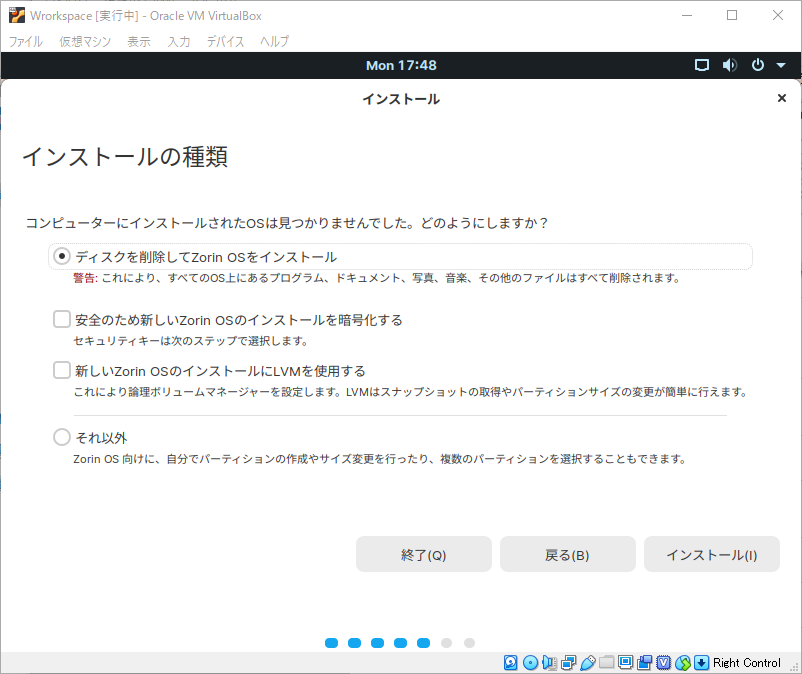
Zorin OS をインストール
このときに他の言語に比べて日本語が読みやすいと感じる方は、日本語を選択しておくと良いと思います。今回はインストールして使うつもりなので、「Zorin OS をインストール」を選択します。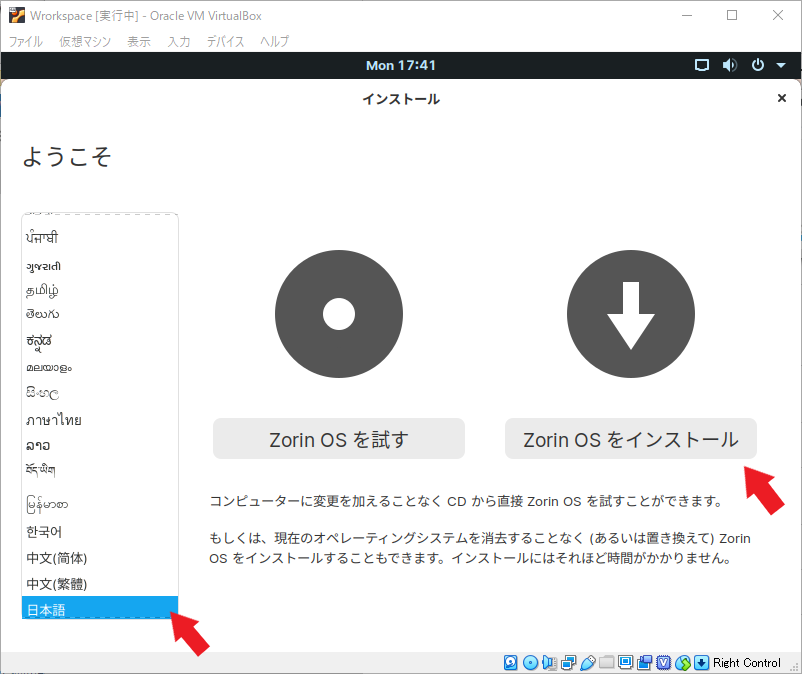
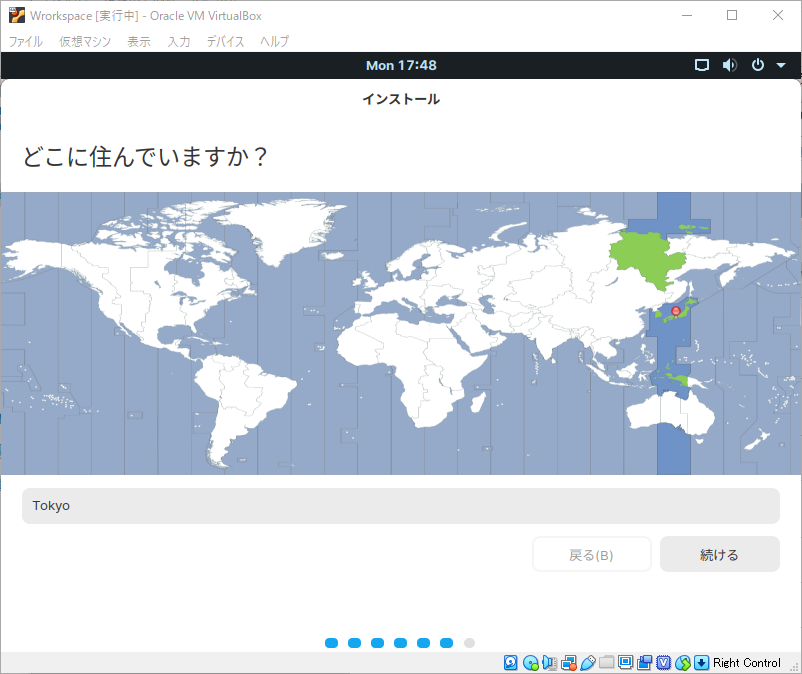
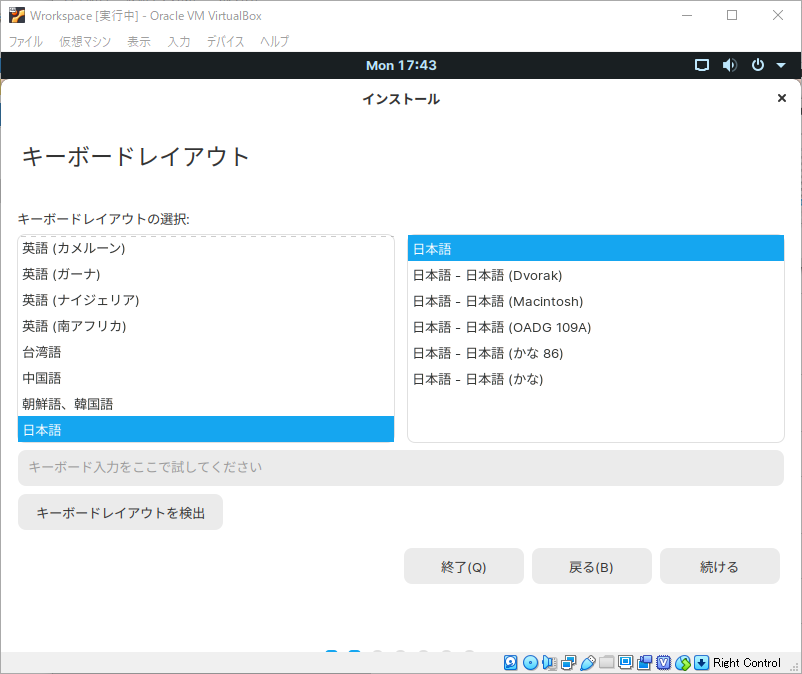
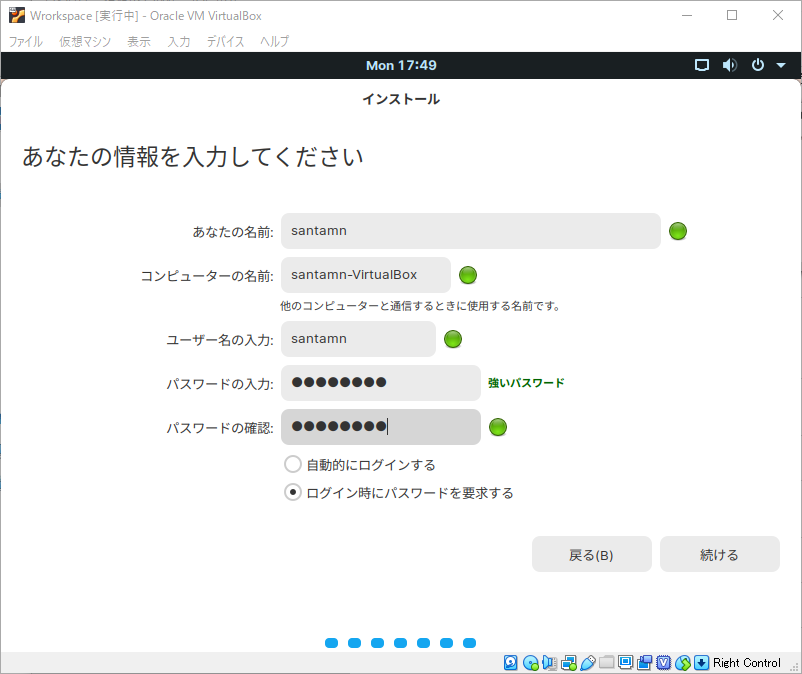
流れに乗って準備を続ける
この後はだいたい説明を読みながら進めていけば大丈夫だと思います。
Guest Addition CD イメージの挿入
クリップボードの共有や解像度の調整ができるように Guest Addition CD イメージの挿入をします。
build-essential のインストール
Guest Addition CD を起動するために gcc や make などが必要なので、これらが入った build-essential を入手します。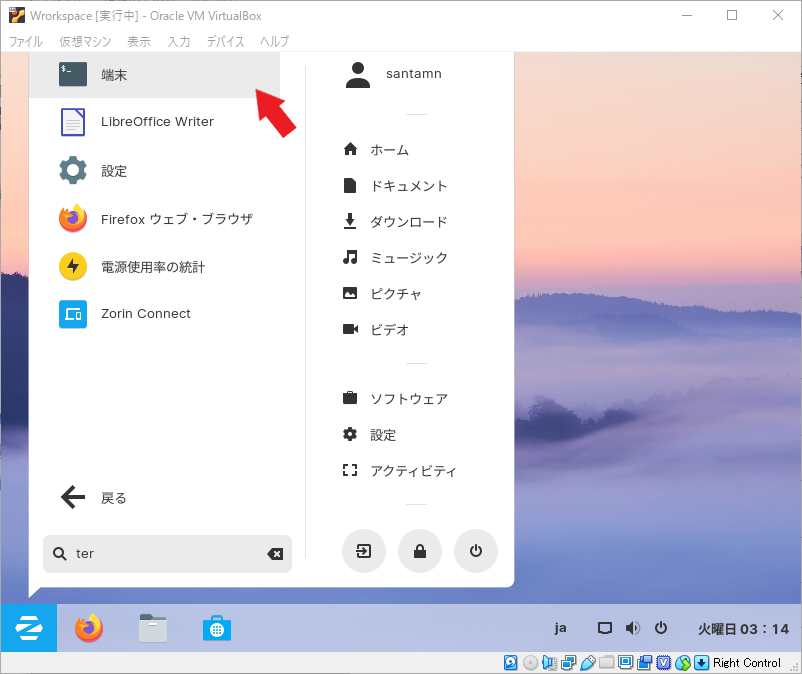
端末を開いて、
$ apt install build-essentialというコマンドを打てば OK です。端末は今後もよく使うことになると思うので、タスクバーに留めておきます。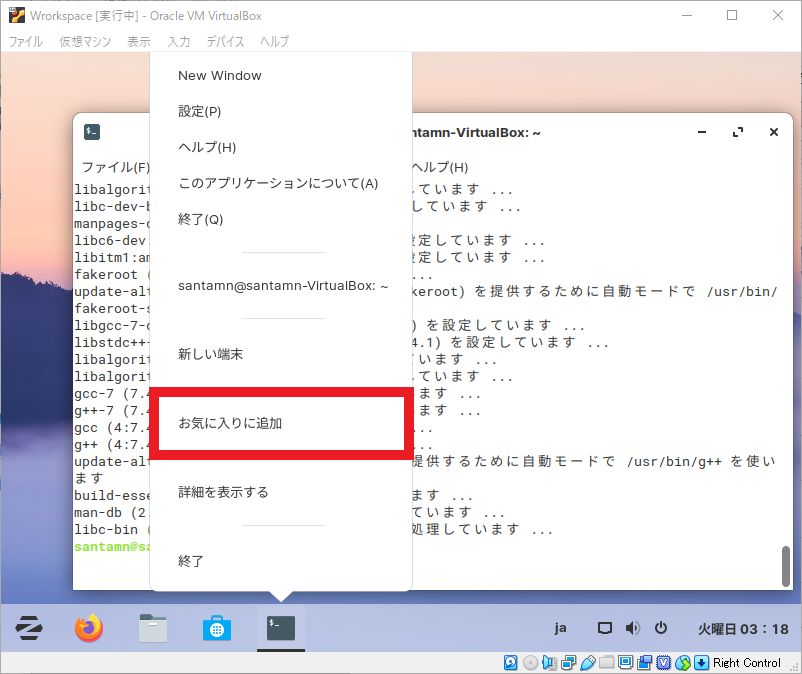
Guest Addition CD イメージの挿入
「Guest Addition CD イメージの挿入」を押下すれば、自動で処理が進みます。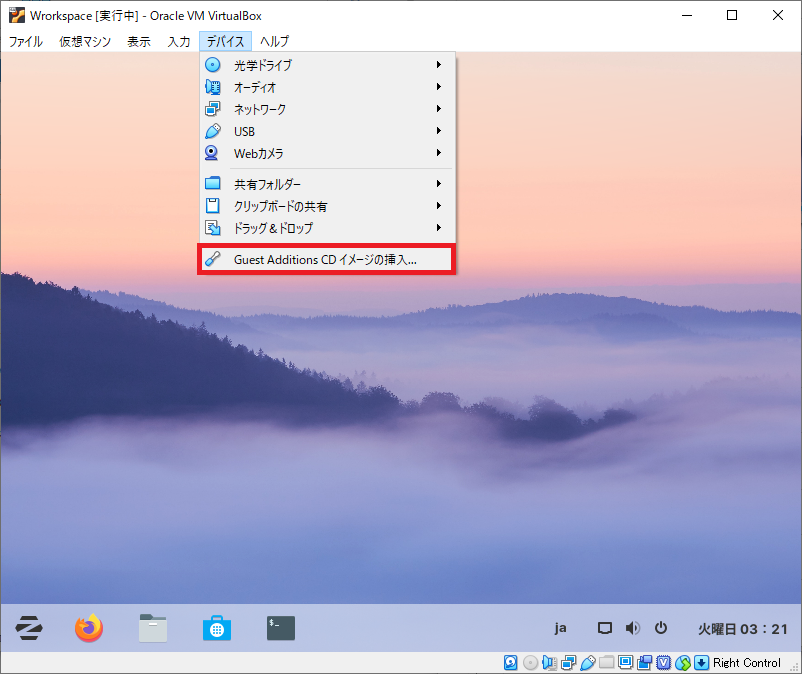
おわりに
今回の記事はほとんどここを参考にしたものです。
なにか間違いや不明な点があればコメントしていただけると幸いです。